Updated on 2016-05-22
https://hadoop.apache.org/docs/r1.0.4/cn/
分布式存储(HDFS),分布式计算(MapReduce)

Hadoop
Hadoop 主要包括 4 个模块
Common:通用的基础程序以支持其他Hadoop的模块。
HDFS:分布式文件系统,它提供对应用程序数据的高吞吐量访问。 (Hadoop Distributed File System)
YARN:一种作业调度和集群资源管理平台,在上面运行分布式计算,典型的计算框架有 MapReduce(批处理) , Storm(流式处理) , Spark(内存计算)。
MapReduce:基于 YARN 系统的大型数据并行计算框架。
Hadoop 的其它一些子项目
Hive™:支持数据汇总和即席查询的数据仓库。
HBase™:一种可扩展的支持大量结构化数据存储的分布式数据库。
Mahout™:一种可扩展的机器学习和数据挖掘库。
Pig™:一个高层次的数据流语言和并行计算框架。
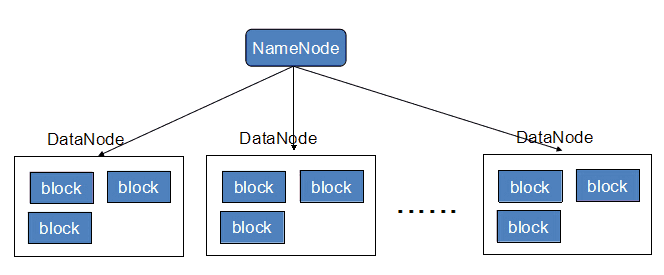
HDFS 架构
- 主从结构(Master , Slaver)
- 主节点,可以有多个 namenode (Activity - Standby)
- 接收用户操作请求,是用户操作的入口
- 维护文件系统的目录结构,称作命名空间
- 管理文件与 block 之间关系,block 与 datanode 之间关系
- 从节点,有很多个 datanode
- 存储文件
- 文件被分成 block 存储在磁盘上
- 为保证数据安全,文件会有多个副本
- 主节点,可以有多个 namenode (Activity - Standby)
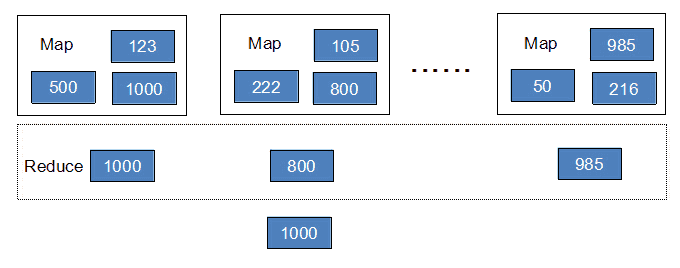
MapReduce 架构
- 主从结构
- 主节点,只有一个 JobTracker
- 接收客户提交的计算任务
- 把计算任务分给 TaskTracker 执行,即任务调度
- 监控 TaskTracker 的执行情况
- 从节点,有很多个 TaskTracker
- 执行 JobTracker 分配的计算任务(Map 映射,Reduce 归约)
- 主节点,只有一个 JobTracker
Yarn 架构
- 主从结构
- 主节点,只有一个 ResourceManager
- 集群资源的分配与调度
- MapReduce、Storm、Spark 等应用必须实现 ApplicationMaster 接口才能被 RM 管理
- 从节点,有很多个 NodeManager
- 单节点资源的管理
- 主节点,只有一个 ResourceManager
Hadoop
[root@master sbin]$ ./start-all.sh #启动 Hadoop 集群
[root@master sbin]$ ./stop-all.sh #停止 Hadoop 集群
start-dfs.sh start-mapreduce.sh
stop-dfs.sh stop-mapreduce.sh
[root@master sbin]$ ./hadoop-daemons.sh #单独启动停止 Hadoop 进程
HDFS 模块启动顺序
* NameNode
* DataNode
* SecondaryNameNode
MapReduce 模块启动顺序
* JobTracker
* TaskTracker
关闭顺序相反
[root@master ~]$ jps #查看 Hadoop 进程
4711 Jps
3867 NodeManager
3435 NameNode
3772 ResourceManager
3528 DataNode
启动 Hadoop 时,如果出现错误信息 `: Name or service not knownstname master`
需要将 hadoop-2.7.0/etc/hadoop/slaves 中的主机名换成 IP 地址,本人推荐一开始就写成 IP 地址
HDFS
[root@master ~]$ hadoop fs
等同于
[root@master ~]$ hdfs dfs
-ls #查看目录结构
-lsr #递归查看目录结构
-du #查看目录下各文件大小
-dus #汇总查看目录下文件大小
-count #统计文件(夹)数量 文件夹 文件 大小
-mv #移动
-cp #复制
-rm #删除
-rmr #递归删除
-put #上传文件
-get #下载文件
-getmerge #下载多个文件并合并
-appendToFile - #通过终端向文件输入内容
-cat #查看文件内容
-text #查看文件内容
-stat #查看文件属性 %b 文件大小 %o block 大小 %r 副本数 %n 文件名 hdfs dfs -stat %b^%o^%n /123.txt
-mkdir #创建文件夹
-touchz #创建空文件
-setrep #修改副本数量 replication(复制)
-chmod #修改权限
-chown #修改用户组
-expunge #清空回收站
-help [cmd] #帮助
[root@master ~]$ hadoop jar hadoop-mapreduce-examples-2.7.0.jar pi 2 2 #运行 MapReduce
[root@master ~]$ hdfs fsck / #文件系统检查工具
-move #移动受损文件到/lost+found
-delete #删除受损文件
-files #显示被检查的文件
-blocks #显示块信息报告
-locations #显示每个块的位置信息
[root@master ~]$ hdfs balancer #平衡 block
[root@master ~]$ hdfs dfsadmin
-report #查看集群状态
-safemode <enter | leave | get | wait> #进入|离开|获知|等待 安全模式