Updated on 2016-06-08
Hive 是 SQL 解析引擎,它将 SQL 语句转译成 Map/Reduce Job 然后在 Hadoop 执行;能够用类 SQL 的方式操作 HDFS 里面数据一个数据仓库的框架,这个类 SQL 我们称之为 HQL(Hive Query Language)。
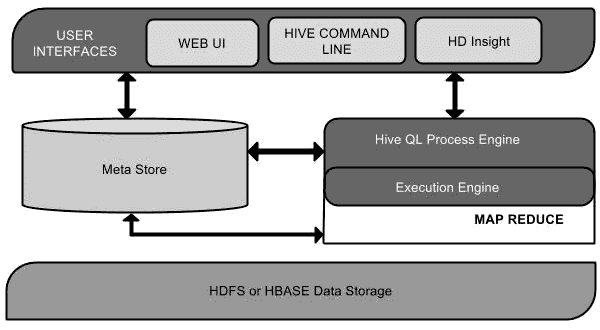
Hive 概念
- Hive 的数据存储基于 HDFS
- Hive 中的表—HDFS 里的目录
- Hive 中的表的数据—HDFS 目录下的文件
- Hive 中的行列—HDFS 文件中的行列
- Hive 的用户接口有三个:Shell、Web、JDBC/ODBC。
- Hive 将元数据存储在数据库中(MetaStore),只支持 MySQL、Derby(默认,一次只能打开一个会话,不推荐)作为存储引擎;元数据包括表的名字、列、分区、是否为外部表以及数据所在目录等。
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成。(包含 _ 查询,但
select _ from table不会生成 MapReduce 任务) - Hive 中的解释器、编译器、优化器完成 HQL 查询语句并生成查询计划;生成的查询计划存储在 HDFS 中,并随后由 MapReduce 调用执行,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。(简单来说就是把类 SQL 语句转化为 MapReduce 任务运行,高延迟)
- Hive 在导入数据过程中不会对数据做任何修改,只是将数据移至 HDFS 目录中,所有数据都是在导入时确定。(纯移动/复制操作)
- 因此 Hive 并不提供实时的查询和基于行级的数据更新操作,不适合联机事务处理(低延迟)。
- Hive 没有定义专门的数据格式,因此创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据。
- 列分割符:’,’ ‘\t’(TAB) ‘\040’(空格) [ASCII码表]
- 行分隔符: ‘\n’(ENTER)
- 文件格式:TextFile(数据是纯文本)、SequenceFile(若需要压缩)
- Hive 中的数据模型有4种:Table(内部表)、Partition(分区表)、External Table(外部表)、Bucket(桶表)
Hive 操作
create database db1; 创建数据库
show databases; 显示数据库
use db1; 切换至 db1 数据库
create table a1(id int,name string) row format delimited fileds terminated by '\t' [stored as textfile]; 创建表并以 TAB 键分割[并存储为纯文本]
create table a1(id int,name string) partitioned by (p string) row format delimited fileds terminated by '\t'; 创建分区表分区字段`p`并以 TAB 键分割
show tables; 显示表名
show partitions a1; 查看表分区
desc a1; 查看表结构
load data [local] inpath '/root/1.txt' [overwrite] into table a1; 导入数据[覆盖]至表中,`local` 表示本地路径
load data [local] inpath '/root/1.txt' [overwrite] into table a1 partition (p='1'); 导入数据[覆盖]至表中,并分区至1文件夹中(需为分区表)
select * from a1; 查询表所有数据
select count(*) from a1; 运行 MapReduce 计算有多少行数据
drop table a1; 删除表
drop database db1; 删除数据库
alter table a1 add columns (age int,date string); 添加2列新字段
alter table a1 replace columns (id int); 替换表中所有字段
alter table a1 rename to a2; 更改表名
create table a1bak like a1; 创建表并复制表结构
create table a1(id int,name string) row format delimited fileds terminated by '\040' location '/123'; 创建表并指定存放位置
dfs -put /root/1.txt /123; 直接上传代替 LOAD 操作
select * from a1; 查询表所有数据
!ls -l; 执行外部命令
dfs -ls /; 执行 dfs 命令
Hive 的历史命令存放在 ~/.hivehistory
MySQL 操作
mysql -uroot -p000000 登录 MySQL
show databases; 显示数据库
create database a1; 创建数据库
use a1; 切换至 a1 数据库
show tables; 显示表名
create table b1(id int(4),name varchar(20),sex char(1)); 创建表
desc b1; 查看表结构
insert into b1 values (1234,'xiaoming','m'); 插入数据
select * from b1; 查询数据
select user,host,password from mysql.user \G; 查询 mysql.user 表数据并以组排列
delete from b1; 删除表中所有数据
delete from b1 where sex='m' 删除表中 sex 为 'm' 的数据
drop table b1; 删除表
drop database a1; 删除数据库
select now(); 查看时间
select version(); 查看版本
grant all on *.* to user1@'%' identified by '123456'; 创建 user1 用户并[赋有所有权限]且可在[任何主机]上[访问所有数据库] on to by
'%' 任何主机 'localhost' 本机
flush privileges; 刷新用户权限表,另一种不推荐方式 `service mysqld restart`
show grants for keystone@'localhost'; 查看用户权限
show variables like 'character%'; 查看数据库字符集
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
MySQL 的配置文件为 /etc/my.conf
[mysqld]
character-set-server=utf8
default-character-set=utf8 (将被弃用)
[client]
default-character-set=utf8
重置 MySQL ROOT 密码
vim /etc/my.conf
[mysqld]
skip-grant-tables
service mysqld restart
mysql -uroot -p123
update mysql.user set password=PASSWORD('123456') where user='root';
导入数据库 mysql> source /root/mysql.sql
导出数据库 mysqldump -uroot -p123 mysql > mysql.sql
service mysqld start 启动 MySQL 服务
chkconfig mysqld on 设置开机启动服务
MySQL 的历史命令存放在 ~/.mysql_history